Humans might typically know that there are no whales on mars or jellyfishes flying through the solar atmosphere. And with the recent research done by the Tooploox team, machines can now also reach this point of enlightenment.
Here at Tooploox, we experiment with neural networks every day. There is no doubt that they are great for understanding images and their context. In the standard neural network, image recognition is done through finding patterns on an image and comparing them to ones known from the training set.
In building deep learning-based image recognition technology, you can simply feed the network an image and expect it to classify it as, e.g., a wolf or dog. More advanced networks will detect the objects and even segment all their instances; see Fig. 1.

As a side effect, it was not only necessary to provide the neural network with a tremendous amount of data, but there developed a risk of finding patterns and identifying objects in some impossible places, much in the same way humans can see a face or an animal in the shape of a cloud. Yet every human child knows that there are no elephants in the sky, while artificial intelligence lacks this experience. It is not a real intelligence after all and there is nothing like “common sense” when it comes to machine learning solutions.
In this post, we present the results of our recent research project — Plugin Networks — introduced in [Michal Koperski, et. al., Plugin Networks for Inference under Partial Evidence] and presented at the WACV 2020 conference. The project source code can be found in this GitHub repository tooploox/plugin-networks.
In this work, we investigate and improve the inference process of neural networks, provided that some partial evidence information is given.
What is partial evidence in AI image recognition
For instance, assume that you own the neural network model classifying the given image (containing the animal) into one of two classes: wolf or dog. The inference process means that your model is already pre-trained (on some training dataset) and you only evaluate its performance on some testing dataset. It means that you can evaluate your model on any photo now and expect it to classify the given image as a wolf or dog.
Now the main assumption comes. Let us consider that you are given some additional information about the photo. For instance, it can be the weather conditions, localization (indoors or outdoors), or the time and date that the photo was taken. We call this information our partial evidence. There are no whales on Mars, right?
But how can we use partial evidence?
Of course, your already pre-trained model cannot read such information. It is commonly not designed to understand it. Moreover, it was not trained with partial evidence. Also, partial evidence data takes a different form – it can be text or a numeric value, instead of an image.
In our recent paper, we present Plugin Networks that you can plug into the pre-trained model, train them very efficiently, and finally make use of partial evidence. What is most important is that the resulting extended network is more accurate on testing datasets (and training, too) as compared to the base model. Additionally, we’ve achieved state-of-the-art results on several tasks including image classification, multiclass classification and semantic segmentation tasks.
In the following sections we describe the problem in more detail.
Pre-training
Such problems as image classification, object detection, and semantic/instance segmentation (see Fig. 1) are often solved through the usage of neural networks, especially when there is a lot of data to train them on.
One can find the following datasets when referring to these problems: ImageNet, MS Coco, or SUN, Pascal VOC. Thus, one can train a neural network using such publicly available datasets from scratch or simply use already pre-trained models taken from Model ZOO (see, e.g., torchvision.models). Using a pre-trained model is a very common approach in computer vision tasks. It can save a lot of time since the process of training the neural network is usually very computationally intensive. One can find the application of pre-trained models in such research topics as: feature extraction, transfer learning, joint learning or continual learning.
Inference under partial evidence
Since we focus exactly on the process which usually follows the training, i.e. inference. Once you have trained your AI image recognition model, you can try to evaluate it by applying it to new (unknown during the training) testing datasets.
Quite often this dataset is much different than the dataset used for training. Hopefully, the fine-tuning process may sometimes adapt your pre-trained model (or at least some its layers) to the new data; see. Fig. 2.

The re-usage of pre-trained models is a common approach for the following techniques: transfer learning, continual learning, joint learning.
It is worth mentioning that our approach is based on the availability of some additional information — partial evidence — about the input image during the inference time. More specifically, we assume that a set of labels corresponding to a given image is known during inference, while the task at hand is to improve the performance of the model on the original task, e.g. image classification, object detection, and semantic segmentation.
This corresponds to a real-life application, where, for instance, we know that the image was captured in a forest or in a cave, which drastically reduces the likelihood of detecting, for instance, a skyscraper. Similarly, information that a given object appears in an image can greatly improve its localization or segmentation.
Plugin Networks
Since partial evidence can be available in multiple forms and modalities, the main prediction system, e.g. a convolutional neural network (CNN), is trained to perform a general purpose prediction with no assumption about the existence of partial evidence or lack thereof. Neural architectures such as CNNs are not modular, thus any modification such as new inputs (partial evidence) or new outputs (new tasks) are difficult to apply without repeating the full training procedure.
Otherwise, phenomena such as catastrophic forgetting may occur. Our objective is to enable the model to incorporate additional available information without re-training the main system while exploiting this information to increase the quality of predictions.
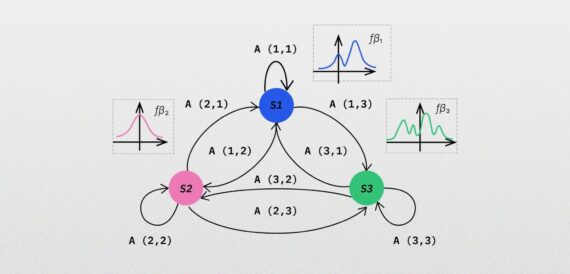
We propose Plugin Networks as a simple extension to the base model which allows for the incorporation of partial evidence during inference. The feedforward process for both original input and partial evidence is depicted in Fig. 3. We tested multiple options for plugging the Plugin Networks into the base model. We also investigated different architectures of base neural network models.

It is worth mentioning that such plugged in networks usually improve the accuracy of the base model. Let us remark that we train only the plugin network. which is usually very small in comparison to the very big base model. Therefore the training process is not computationally intensive any longer.
Experiments
Our experiments consist of plugging the multiple layered neural networks (in short MLP) into deep MLP, convolutional, and recurrent neural networks, respectively. Below we summarize only the main results of our research, which are described in more detail in the paper [Michal Koperski, et. al., Plugin Networks for Inference under Partial Evidence, arXiv paper].
Hierarchical Scene Categorization
We apply our method on the SUN397 dataset [28, 27]. The dataset is annotated with 3 coarse categories, 16 general scene categories, and 397 fine-grained scene categories. Our task is to classify each of the fine-grained categories, given true values for coarse categories. We split the dataset into train, validation, and test, split with 50, 10, and 40 images per scene category.
For the base model we chose the AlexNet network following the approach in [H. Hu, et. at., Learning structured inference neural networks with label relations, CVPR, 2016] and [T. Wang, et. al.. Feedback-prop: Convolutional neural network inference under partial evidence, CVPR, 2018]. The baseline model performance is about 52.83 (MC accuracy) and 56.17 (mAP precision) while the latter paper, which represented the state-of-the-art results, about 54.94 (MC acc) and 58.70 (mAP). Let us remark that our method outperforms the state-of-the-art on all reported metrics — 57.59 (MC acc) and 61.55 (mAP); see Tab. 1. We refer to our paper for more details about the comparison.

Multi-label Image Annotation
As a part of AI image recognition process we also tested our method on multi-label image annotation tasks using a well-known COCO dataset. It contains 120,000 images, each annotated with five caption sentences. The task is to predict a predefined set of words explaining an image, which after the pre-processing (tokenization, lemmatization and stop-words removal) is simply represented by the vector of 1000 binary numbers (occurrence of words in the captions). For this experiment, for the base network, we chose several ResNet-18 architectures to stay consistent with the authors of the aforementioned Feedback-prop method.
We show that the performance of the baseline model (23.00 mAP) and the latest state-of-the-art model (25.70 mAP) can be beaten with Plugin Networks (27.97 mAP) without any sophisticated effort. Our result can be even better (30.13 mAP) if we choose the deeper ResNet architecture.

Scene semantic segmentation
In our last experiment we evaluated the Plugin Networks on a multi-cue object class segmentation task, which mainly consisted of finding the location of objects (and recognizing their class) on a given image; see Fig. 4. For this purpose, we considered the dataset from Pascal Visual Object Classes Challenge (VOC dataset), split it into 8498 and 736 images for training and validation, respectively. We took a fully convolutional network (FCN) as the base model and experimented by adding several plugins to its architecture. We consider FCN-8s model (pre-trained on the SBD dataset) as a baseline model.

The common metric to measure the performance of the model for semantic segmentation tasks is intersection over union (IoU).
The baseline model results in an IoU score of 65.5%. It is again worth mentioning that our methods outperform the, so far, best known results, gaining the score of about 72.2%. Few graphical examples are depicted in Fig. 5. We highly encourage and invite you to see further details in our paper.
Conclusions
In our work, we introduced the Plugin Networks – a simple, yet effective method to exploit the availability of partial evidence in the context of visual recognition tasks. Plugin Networks are integrated directly with the intermediate layers of pre-trained convolutional neural networks and, thanks to their lightweight design, can be trained efficiently with low computational cost and a limited amount of data.
Results presented on three challenging tasks and various datasets show the superior performance of the proposed method with respect to the state-of-the-art approaches. We believe that this work can open novel research directions related to solving visual recognition tasks with partial evidence, as our Plugin Networks are agnostic to input signals and can accommodate arbitrary modality of the input data, including audio or textual cues.
Therefore, their multimodal nature can allow richer contextual cues to be taken into account in the inference procedure, leading to more effective and efficient visual recognition models.