One of the biggest challenges in machine learning is getting sufficient amount of labeled data to train the models. You can develop extraordinary ML model, but small dataset or its low quality will make all your efforts useless. You can easily solve this issue when you have a system that receives the information about your customers whose every action provides you with the labeled data you need. Things are getting harder when you don’t have the possibility or time to get and label your data.
This concern arises when you want to start the adventure with autonomous driving. Without great deal of sensors attached to the car, you are not able to collect appropriate dataset – even the image from the ordinary camera placed on the car needs to be labeled, which is definitely not the task anyone is willing to do. How about using the existing, open data? In this article I’ll guide you through the most interesting available datasets you could use to master your skills in autonomous driving.
What are we looking for?
A good system for autonomous car has many features. Remember we are talking about replacing the human sitting behind the wheel with the computer. It should adapt to the weather conditions, current situation on the road, watch for other vehicles driving around, detect pedestrians and traffic signs. It is very hard to find an open dataset covering all those aspects. Fortunately there is quite a satisfying range of data sources that focuses on different aspects of self-driving cars.
KITTI is the name that everyone interested in autonomous driving should know. Specialist from the Karlsruhe University of Technology noticed that only simple and collected in controlled environments datasets were available. It was a starting point for their idea to use autonomous car platform to collect data that would be used as a benchmark for computer vision algorithms. They drove around city of Karlsruhe with their car equipped with four high-resolution cameras, localization systems and a laser scanner. They provide decent amount of data to perform object detection, stereo visual odometry or scene flow. KITTI is a broadly recognized benchmark for testing different algorithms.
Learn to control the car
There are several datasets that aim at learning car control. They provide videos grabbed from camera mounted in front of the car driving around cities. Every frame of those videos comes with annotations to car speed, acceleration, GPS position, steering angles and much more. There is a pretty good choice of those sets available for free. George Hotz, the founder of comma.ai decided to release 7.5 hours of driving data along with labels concerning vehicle state. Specialists from Oxford Robotic drove 10-kilometer route through the central Oxford twice a week from November 2014 to December 2015 with their NISSAN Leaf platform. Such a vast period of data collection resulted in datasets produced in every possible weather conditions. The cameras mounted on their car provided 20 million of images along with information from LIDAR or GPS sensors.
Still looking for other datasets? A few months ago Udacity released 223 gigabytes of data containing frames of 70 minutes videos in total recorded while driving around Mountain View. The advantage of this dataset is its diversity – videos for either sunny and overcast weather conditions are included. With every frame comes information about car position, current speed, steering angle, throttle or brake. Unrealistic for other geography datasets with perfect roads were the motivation for collection of a new dataset by Hayet y Guzman from University Guanajuato in Mexico. They realized that most of available road datasets lack several features like abundant potholes or speed bumpers – elements that are typical of developing countries. During the summer of 2014 they grabbed stereo video and provided it along with gps and acceleration data.
Object Detection
As self-driving vehicle moves around the city, it should be able to detect objects in the whole scene, especially all the road users such as pedestrians, cyclists or other cars. In terms of object recognition a very interesting dataset, Cityscapes, was released in the 2016 by group of specialists from Germany. This is the continuation of Daimler Urban Segmentation Dataset. It provides around 25 000 photos taken in 50 cities. Every pixel of each photo is annotated to belong to one of 30 defined classes such as roads, sidewalks, vehicles, traffic signs or people. Photos were taken at daylight in different months of the year.
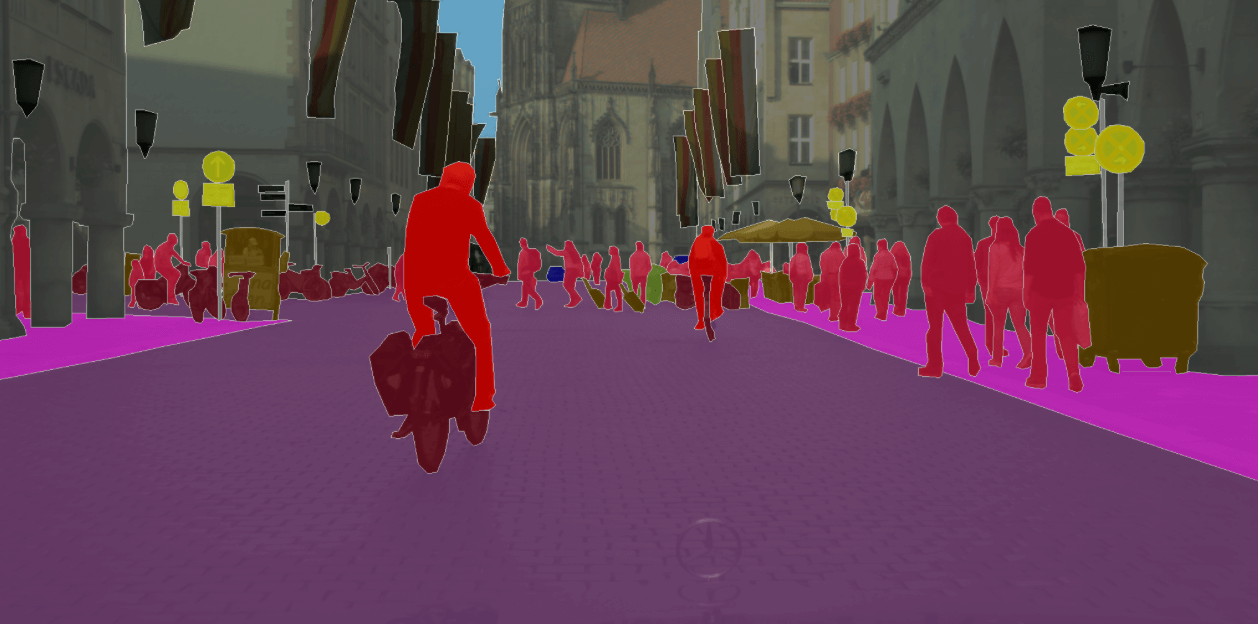
Labeled image from Münster – Cityscapes
There is also a similar dataset that ADAS group generated artificially. It’s called Synthia – Synthetic Collection of Imagery and Annotations. It consists of about 200 000 photo-realistic frames obtained from virtual city, with pixel-wise annotations of 13 classes in total. The way Synthia is created permitted authors to generate huge amount of multiple different weather conditions along with good scene diversity ranging from modern city to green areas.
Another artificially generated dataset is a variation of Kitti dataset – Virtual KITTI provided by Xerox. It includes fully-annotated 21 260 frames created using Unity game engine and may serve different purposes connected with the autonomous driving: object detection and multi-object tracking, scene-level and instance-level semantic segmentation, optical flow, and depth estimation.
Part of virtual KITTI dataset
Annotated pedestrians are part of datasets for the above mentioned semantic segmentation. There is also a bunch of sources that address only this issue. Elektra or Daimler offer that kind of images. JAAD Dataset provides also labels for object behaviour. Here you can find another interesting dataset. Authors focus on the problem of small, unexpected obstacles on the road.
Traffic signs
That’s another thing to handle. The main difference between traffic signs and other elements of the roads is their country-dependence. Every state has its own set of traffic signs. Datasets that are worth looking at come from countries such as Belgium, Germany or United States. Car system firstly detects them on the scene, and then classifies them. With occlusions and changes in illumination it’s a non-trivial task.

Part of the dataset provided by Ruhr-Universitat Bochum
Testing your models
Ok, so now you are able to choose dataset for further processing. Let’s say you trained a model. What’s next? You don’t need to incorporate the whole bunch of sensors and software to your car. You can test performance of your autonomous algorithm on simulators that are available. Udacity is building an open-source self-driving car and is looking for people around the world to contribute to the project. That is why they provide useful resources. Among those assets you can find Self-Driving Car Simulator, which is the testing environment for Udacity Nanodegree program mentioned by my colleague in the previous blogpost about autonomous driving.

Udacity simulator
Another simulator you could use is TORCS, a racing simulator which is popular for AI research thanks to the source code available. That makes it pretty easy to get access to the driving indicators and race conditions. You can choose from 42 different cars riding around 30 various tracks. There is also an interesting TORCS-related tutorial to write your own program controlling the car during races. The simulators are pretty good for car control, but they are racing games. How about simulating real city traffic? A very interesting project is being developed by open.ai. They provide a platform for training AI agents across numerous computer games. Those agents are allowed to use the computer like human does. Agents take screen pixels as input and is able to use a virtual mouse or keyboard. That is a very good way to playing with the reinforcement learning!
Other simulators
There is still a shortage of open-source solutions, but you may find some interesting projects like ChosunTruck or Autoware. ChosunTruck is an Euro Truck Simulator 2 that allow you to control vehicle in an environment that is much closer to usual city traffic conditions. This is an advantage over race-based simulators. Autoware, maintained by Tier IV, is a software for urban driverless car and supports quite a good range of tasks: 3D localization, object detection, path planning and following, lane detection are just examples.
There is a vast amount of possible sources to start playing with autonomous driving. You don’t need a car with multiple sensors mounted everywhere. You can begin your self driving car adventure with datasets that are already prepared.